Général
https://archive.kernel.org/oldwiki/btrfs.wiki.kernel.org/index.php/Main_Page.html
Se gère avec la commande btrfs et ses sous-commandes.
Penser à
man btrfs subcommand
Installation
sudo apt install btrfs-progs
Formatage et label
sudo mkfs.btrfs /dev/sdX1 -L "Label"
btrfs filesystem label /media/BTRFS ["Nouveau label"]
Infos
sudo btrfs filesystem show /media/BTRFS
Utilisation espace
btrfs filesystem df /media/BTRFS
btrfs filesystem df /media/BTRFS
sudo btrfs filesystem usage
Attention, d’autres outils peuvent renvoyer des infos incorrectes.
Comme ncdu qui ne prend pas en compte la deduplication.
Vérification
btrfs check /dev/sdX
man btrfs check
Volumes
https://man7.org/linux/man-pages/man8/btrfs-subvolume.8.html
Un (sous-)volume est une arborescence de fichiers autonome.
Chaque volume a son propre espace d’inodes. Il peut donc y en avoir des inodes identiques au sein de différents volume.
L’inode d’un volume est toujours 256.
La racine du FS est elle-même un sous-volume, appelé top-level, avec un ID de 5. Ce sous-volume ne peut pas être supprimé/remplacé.
Un volume peut être monté indépendemment du reste du FS btrfs auquel il appartient, via l’argument
subvol=/@mysubvolume ou subvolid=257
Il est sinon possible de parcourir un sous-volume comme un simple dossier si son dossier parent est accessible dans l’arborescence.
Organisation
Une convention est de nommer les volumes @myvol. Ce n’est pas une obligation de commencer par @, mais très fréquemment utilisé.
On peut choisir de créer les volumes à la racine du top-level puis de les monter au sein de / (volumes “flat”), ou bien de les créer directement au chemin où ils doivent être accessibles, imbriqués dans un autre volume (volumes “nested”).
L’organisation flat correspond assez bien au fonctionnement de btrbk (voir plus loin). Elle est aussi pratique pour avoir un bon aperçu des volumes utilisés au sein d’un FS, et pour s’assurer de leur bonne sauvegarde. Mais ils ont besoin d’être montés dans le fstab (ou autrement).
Le principal avantage que je vois aux volumes nested, c’est d’être directement au bon emplacement, tout en étant exclus des snapshots. Ça me semble bien pour les dossiers temporaires, avec de la donnée qui sera recréée automatiquement si elle est absente, comme les dossiers de cache. Pas besoin de les monter.
Quelques dossiers qui peuvent être intéressants à mettre en sous-volume :
/var/log//var/cache$HOME/.cache
Swap
On peut faire un swapfile sur btrfs. Pour ça, il faut créer un sous-volume dédié et désactiver le CoW (voir plus bas) puis faire
btrfs filesystem mkswapfile --size 2G ./swapfile
https://btrfs.readthedocs.io/en/latest/Swapfile.html
Lister les volumes
sudo btrfs subvolume list /media/BTRFS
liste tous les volumes du FS btrfs.
L’argument doit être le point de montage, pas un sous-dossier ou un sous-volume.
Volume par défaut
Lorsqu’on monte simplement la partition BTRFS, sans plus de précision, c’est un certain volume qui sera monté. C’est généralement le volume top-level, avec un id de 5, mais ceci peut se vérifier et se changer.
sudo btrfs subvolume get-default /media/BTRFS
Suppression
sudo btrfs subvolume delete /path/to/@subvol
Il est possible que l’espace ne soit pas récupéré immédiatement (lié au no-commit ?).
On peut forcer la récupération avec la commande sync.
Il est possible de simplement rm -R /path/to/@subvol , mais c’est beaucoup plus long (chaque fichier est supprimé, alors que la suppression du volume est quasi-instantanée).
Snapshots
Un snapshot est simplement un volume, qui a été initialisé avec les données déjà présentes dans le volume source.
Pour les créer :
sudo btrfs subvolume snapshot -r ./@sourcevol ./@snapshot/@backupvol
Le -r sert à mettre le snapshot en lecture seule. On peut l’enlever si on souhaite l’avoir en lecture-écriture.
Il est impératif que la destination soit sur le même FS btrfs.
Un snapshot ne prendra pas les données des sous-volumes nested !
Le volume nested se retrouve dans le snapshot avec un inode 2 ; il n’est pas listé dans les volumes du FS.
Il est transféré à nouveau sous forme d’inode 2 lors d’un snapshot depuis le snapshot.
Suppression
C’est un volume normal, donc btrfs subvolume delete.
Deduplication
https://btrfs.readthedocs.io/en/latest/Deduplication.html
send et receive
send ne peut être utilisé que sur un sous-volume.
CoW et limitations
Le Copy-on-Write permet d’assuer une meilleure intégrité des données, mais au prix d’une baisse de performance, et éventuellement de fragmentation.
Certains contextes bénéficient de la désactivation du CoW, notamment les gros fichiers et/ou à écriture très fréquentes.
Notamment, les VM et les bases de données : l’utilisation intensive favorise la fragmentation, dégrade les perfs, et peut grandement augmenter l’espace utilisé. Voir notamment l’espace UNREACHABLE dans btdu.
J’ai l’impression que le dossier ImapMail d’un profil Thunderbird peut aussi gagner à être mis en nodatacow (il peut être recréé à partir des serveurs si nécessaire).
Il est possible de désactiver le CoW lors du montage du volume, mais tous les volume du même FS seront alors montée en nodatacow (et donc nodatasum).
Une autre possibilité est de positionner l’attribut nodatacow sur un dossier (qui peut être un sous-volume).
L’attribut nodatacow sur btrfs est C.
Pour lister les attributs :
lsattr ./file
lsattr -d ./folder/
Pour positionner l’attribut nodatacow :
chattr +C ./
S’il est positionné sur un dossier, alors tous les nouveaux fichiers crées dedans le possèderont aussi ; mais les fichiers existants ne seront pas affectés (sauf les fichiers vides).
Pour changer le status CoW d’un fichier, il y a l’obligation de le réécrire complètement.
Dynamiques de copie/déplacement
Lorsqu’on coupe/colle, il est possible que le fichier soit instantanément déplacé, ou bien qu’il doive être réécrit complètement.
Voici un petit tableau récapitulatif du comportement des transferts :
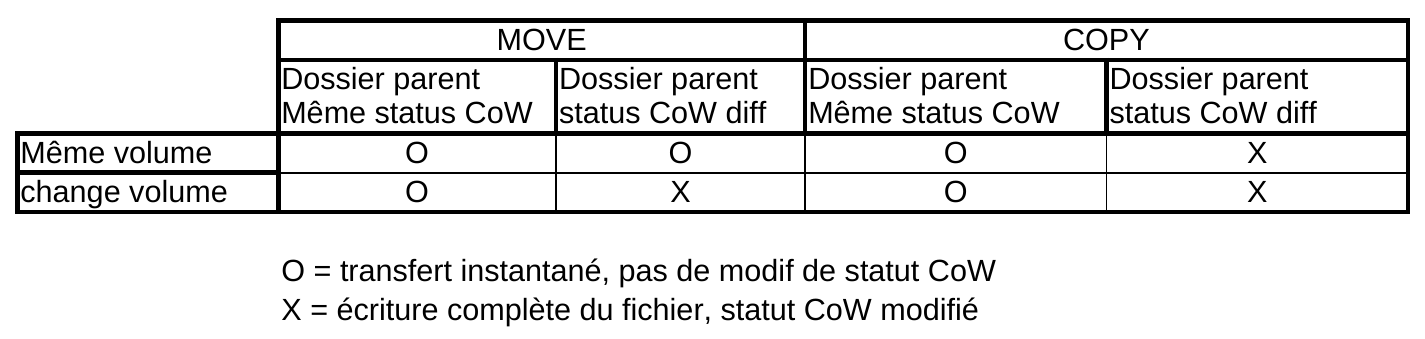
Pour la copie, la réécriture est directement liée au statut CoW du dossier de destination : s’il différe de celui du fichier, alors il y a réécriture.
Pour un déplacement, tant qu’on reste dans le même volume, le status CoW n’est pas modifié.
Mais dès que le volume change ET le dossier de destination a un statu CoW différente, alors il y a réécriture.
On note que 2 déplacements successifs peuvent produire un résultat différent d’un seul déplacement direct.
Par exemple, si on a l’arborescence :
---------------------- @cow
---------------------- @cow/TEST.iso
---------------------- cow
---------------C------ @nocow
---------------C------ nocow
et qu’on déplace TEST directement dans nocow, il est intégralement réécrit et on obtient : s
---------------------- @cow
---------------------- cow
---------------C------ @nocow
---------------C------ nocow
---------------C------ nocow/TEST.iso
Mais si on le déplace d’abord dans cow, puis dans nocow, le changement de volume se passe sans changement de CoW, puis on reste dans le même volume ; les 2 transferts sont instantanés et on obtient :
---------------------- @cow
---------------------- cow
---------------C------ @nocow
---------------C------ nocow
---------------------- nocow/TEST.iso
btrbk
https://github.com/digint/btrbk
Le principe général de btrbk, c’est de lire un fichier de conf, et d’exécuter une/des actions selon ce fichier de config.
La config va définir une ou plusieurs sources, répertoires de snapshots et répertoires de backups.
Dans la terminologie btrbk, un “snapshot” est un snapshot btrfs en read-only (un versionning sur le même disque) ; et un “backup” est un sous-volume en read-only créé sur un autre FS btrfs via send/receive (la copie sur un 2e disque).
L’appel se fait sous la forme :
btrbk -c /path/to/btrbk.conf [action] [filter] [-v] [-n] [-S] [--progress]
Les options -v (verbose) -n (dryrun, modifications non effectuées) et -S (pour afficher les raisons de conservation de chaque snapshot/backup) sont utiles pour mettre en place le fichier de conf et la rotation.
Il y a bien sûr d’autres options, mais celles-ci m’ont été très utiles.
Les actions peuvent être :
run: fait les snapshots, puis les backups, puis le nettoyage des versionsdryrun: montre les snapshots et les backups qui auraient été créés, mais sans rien écrire ; équivalent àrun -nsnapshot: fait les snapshots et le nettoyage, ignore les backupsresume: ne crée aucun snapshot, mais fait les backups et le nettoyage de versions (snaps + backups)prune: fait uniquement le nettoyage des versionsarchive: copie récursivement tous les volumes depuis la source vers la cible (??)clean: supprime les backups incorrects (qui ne se sont pas terminés avec succès)
Un récap de l’effet de chaque action est dispo dans le man :
Command Option S+ B+ S- B-
--------------------------------------------
run x x x x
run --preserve x x
run --preserve-snapshots x x x
run --preserve-backups x x x
snapshot x x
snapshot --preserve x
resume x x x
resume --preserve x
resume --preserve-snapshots x x
resume --preserve-backups x x
prune x x
prune --preserve-snapshots x
prune --preserve-backups x
D’autres commandes, informatives, sont disponibles : stats, list, usage, etc. Voir man
Quant au filtre, s’il est présent, va n’appliquer l’action demandée qu’aux sections concernées par le filtre.
Attention, il ne s’applique pas qu’au groupe ! Il s’applique aussi aux sections (target, volume et subvolume).
Ainsi, la section target /media/backup sera incluse dans le spectre du filtre backup.
btrbk.conf
man btrbk.conf
Les éléments de ce fichier de conf se séparent en 2 catégories :
- les sections (volume, subvolume et target)
- les options (qui spécifient le fonctionnement de btrbk)
Concernant les sections :
volume est facultatif ; représente le chemin dans lequel on travaille. Pour une structure flat, c’est typiquement le point de montage du top-level ; si l’option est absente, il faut nécessairement mettre un chemin absolu pour l’option subvolume (et target ?)
subvolume : le sous-volume (au qui sera snapshotté) ; typiquement @rootfs ou @home
target : le dossier (autre FS btrfs) dans lequel sera transféré le snapshot, via send/receive ; s’il est absent, btrbk ne fera que des snapshots.
Les options sont nombreuses. Chaque option s’applique à la section à laquelle elle appartient, ainsi qu’à toutes les sections contenues dans celle-ci.
Par exemple, avec le fichier suivant :
volume /btrfs_slash
snapshot_dir @snapshots
subvolume @rootfs
group snap
target /media/user/BACKUP
subvolume @log
l’option snapshot_dir s’applique à la section /btrfs_slash, et donc aussi aux 2 sections subvolume.
En revanche, l’option group et la sous-section target s’appliquent au sous-volume @rootfs uniquement.
snapshot_dir : le dossier qui contiendra les snapshots (local, même FS btrfs) créés par btrbk ; s’il est absent, le snapshot sera créé à côté du volume d’origine, mais avec la date ajoutée
group : permet d’assigner une “catégorie” à une section, pour pouvoir ensuite l’appeler en filtrant ; le nommage est libre
Durée de conservation
Celle-ci se définit via les options :
snapshot_preserve_min latest
snapshot_preserve 48h 30d 12w 24m *y
target_preserve_min latest
target_preserve 0h 60d 20w 24m *y
À lire, pour les snapshots par exemple :
- conserver 1 snapshot par heure pendant 48h
- conserver le 1er snapshot de la journée pendant 30 jours
- conserver 1 snapshot par semaine pendant 12 semaines
- conserver 1 snapshot par mois pendant 24 mois
- conserver 1 snapshot par an
À noter qu’il peut y avoir moins de versions que le nombre spécifié, si certains snapshots ont été sautés. Par exemple, le nettoyage peut supprimer un snapshot vieux de 49h, même si il n’y a que 24 snapshots horaires car le poste était éteint pendant 24h.
Les valeurs _min sont définies par défaut à all, empêchant de fait un nettoyage des versions si on ne le spécifie pas.
En mettant latest, c’est l’opposé, on ne force que la conservation du dernier snapshot.
Nettoyage et target
En cas d’appel à une section incluant une section target, si le chemin de la target est introuvable (par ex. disque débranché), btrbk fera bien les snapshot, mais ne fera ni les backups, ni le nettoyage des snapshots ; et ce même si on appelle l’action snapshot.
Comme il ne connaît pas les backups présents sur la target, il conserve tous les snapshots en local, quel que soit la planification de backup prévue.
Si une tache est planifiée tous les jours voire toutes les heures, avec un disque de sauvegarde régulièrement débranché, les snapshots peuvent alors s’accumuler, et augemnter sensiblement l’espace disque occupé.
Si on souhaite effectuer le nettoyage des snapshots, même en l’absence du disque, on peut alors mentionner le même volume 2 fois, mais dans des groupes différents, et les appeler séparément. Par exemple :
volume /btrfs_slash
snapshot_dir @snapshots
subvolume @rootfs
group snap_only
subvolume @rootfs
group backup_only
snapshot_create no
target /media/user/BACKUP
permet de séparer l’appel des snapshots (avec nettoyage auto) de la partie backup (pour laquelle on désactive la création de snapshot).
Il suffira de choisir entre les filtres snap_only et backup_only.
Ceci risque de supprimer des snapshots avant qu’ils ne se retrouvent sur le disque externe en tant que backups, et donc de créer des trous dans l’historique des backups. Mais la possibilité existe, et permet un nettoyage automatique des snapshots pour éviter la saturation d’espace disque.
À noter que l’option snapshot_create no désactive la création de snapshot en cas d’appel run, mais un snapshot sera quand même créé si l’action appelée est snapshot.
btdu
Utilitaire 3d party pour un genre de ncdu
https://github.com/CyberShadow/btdu/
Il analyse le FS en collectant des échantillons au hasard. Plus on le laisse tourner et + il est précis, mais il consomme beaucoup de CPU.
Il nécessite les droits root.
p pour mettre l’analyse en pause
--max-time=DURATION pour interrompre l’analyse après la durée spécifiée. Il faut spécifier l’unité (s, m, h, d … )
--headless pour ne pas avoir d’interface ; affiche les résultats en texte à la fin de l’exécution. Si pas de durée max, il faudra l’interrompre avec Ctrl-C
--expert pour avoir des infos détaillées sur l’allocation de l’espace
On peut exporter les résultats pour les examiner plus tard, avec --export=results.btdu.
ATTENTION, si btdu est lancé avec l’interface, il faut quitter avec q et non Ctrl-C, sinon l’export n’est pas fait !
Il y a 2 formats d’enregistrement :
- le format
.btdu, qui contient l’intégralité des informations récupérées lors de l’analyse, mais est + volumineux - le format
.json, avec moins d’infos (les infos enregistrées dépendent notamment du flag expert)
Le format est déduit de l’extension, ou spécifié avec--export-format
On peut aussi spécifier--dupour une sortie conforme au format de sortie de du.
On pourra rouvrir ce fichier plus tard en utilisant --import results.btdu au lieu du chemin. On peut appliquer des otions comme headless, expert etc.
autres
taille metadata ?
https://mpdesouza.com/blog/btrfs-for-mere-mortals-inode-allocation/